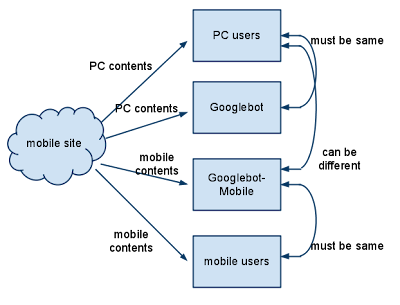
When a mobile user or crawler (like Googlebot-Mobile) accesses the desktop version of a URL, you can redirect them to the corresponding mobile version of the same page. Google notices the relationship between the two versions of the URL and displays the standard version for searches from desktops and the mobile version for mobile searches. If you redirect users, please make sure that the content on the corresponding mobile/desktop URL matches as closely as possible. For example, if you run a shopping site and there's an access from a mobile phone to a desktop-version URL, make sure that the user is redirected to the mobile version of the page for the same product, and not to the homepage of the mobile version of the site. We occasionally find sites using this kind of redirect in an attempt to boost their search rankings, but this practice only results in a negative user experience, and so should be avoided at all costs.On the other hand, when there's an access to a mobile-version URL from a desktop browser or by our web crawler, Googlebot, it's not necessary to redirect them to the desktop-version. For instance, Google doesn't automatically redirect desktop users from their mobile site to their desktop site, instead they include a link on the mobile-version page to the desktop version. These links are especially helpful when a mobile site doesn't provide the full functionality of the desktop version -- users can easily navigate to the desktop-version if they prefer.
Some sites have the same URL for both desktop and mobile content, but change their format according to User-agent. In other words, both mobile users and desktop users access the same URL (i.e. no redirects), but the content/format changes slightly according to the User-agent. In this case, the same URL will appear for both mobile search and desktop search, and desktop users can see a desktop version of the content while mobile users can see a mobile version of the content.However, note that if you fail to configure your site correctly, your site could be considered to be cloaking, which can lead to your site disappearing from our search results. Cloaking refers to an attempt to boost search result rankings by serving different content to Googlebot than to regular users. This causes problems such as less relevant results (pages appear in search results even though their content is actually unrelated to what users see/want), so we take cloaking very seriously.So what does "the page that the user sees" mean if you provide both versions with a URL? As I mentioned in the previous post, Google uses "Googlebot" for web search and "Googlebot-Mobile" for mobile search. To remain within our guidelines, you should serve the same content to Googlebot as a typical desktop user would see, and the same content to Googlebot-Mobile as you would to the browser on a typical mobile device. It's fine if the contents for Googlebot are different from the one for Googlebot-Mobile.One example of how you could be unintentionally detected for cloaking is if your site returns a message like "Please access from mobile phones" to desktop browsers, but then returns a full mobile version to both crawlers (so Googlebot receives the mobile version). In this case, the page which web search users see (e.g. "Please access from mobile phones") is different from the page which Googlebot crawls (e.g. "Welcome to my site"). Again, we detect cloaking because we want to serve users the same relevant content that Googlebot or Googlebot-Mobile crawled.
Peter: It's understandable that webmasters find watermarking images beneficial.Pros of watermarked imagesPhotographers can claim credit/be recognized for their art.Unknown usage of the image is deterred.If search traffic is important to a webmaster, then he/she may also want to consider some of our findings:Findings relevant to watermarked imagesUsers prefer large, high-quality images (high-resolution, in-focus).Users are more likely to click on quality thumbnails in search results. Quality pictures (again, high-res and in-focus) often look better at thumbnail size.Distracting features such as loud watermarks, text over the image, and borders are likely to make the image look cluttered when reduced to thumbnail size.In summary, if a feature such as watermarking reduces the user-perceived quality of your image or your image's thumbnail, then searchers may select it less often. Preview your images at thumbnail size to get an idea of how the user might perceive it.
Pros of watermarked imagesPhotographers can claim credit/be recognized for their art.Unknown usage of the image is deterred.
Findings relevant to watermarked imagesUsers prefer large, high-quality images (high-resolution, in-focus).Users are more likely to click on quality thumbnails in search results. Quality pictures (again, high-res and in-focus) often look better at thumbnail size.Distracting features such as loud watermarks, text over the image, and borders are likely to make the image look cluttered when reduced to thumbnail size.
Peter: Nope. The presence of a watermark doesn't itself cause an image to be ranked higher or lower.
Googlebot may not be able to find your site Googlebot, our crawler, must crawl your site before it can be included in our search index. If you just created the site, we may not yet be aware of it. If that's the case, create a Mobile Sitemap and submit it to Google to inform us to the site’s existence. A Mobile Sitemap can be submitted using Google Webmaster Tools, in the same way as with a standard Sitemap.
Googlebot may not be able to access your site Some mobile sites refuse access to anything but mobile phones, making it impossible for Googlebot to access the site, and therefore making the site unsearchable. Our crawler for mobile sites is "Googlebot-Mobile". If you'd like your site crawled, please allow any User-agent including "Googlebot-Mobile" to access your site. You should also be aware that Google may change its User-agent information at any time without notice, so it is not recommended that you check if the User-agent exactly matches "Googlebot-Mobile" (which is the string used at present). Instead, check whether the User-agent header contains the string "Googlebot-Mobile". You can also use DNS Lookups to verify Googlebot.
Update: The described product or service is no longer available.
Enter your email address:
Delivered by FeedBurner